2 コンソールとコマンド
2.1 コマンド
プロンプトに対して渡すコマンドの基本形を見てみましょう。
2.1.1 四則演算
プロンプトに対して、通常の四則演算式を入力すれば、 電卓変りに使うことが出来ます。
# 四則演算
(350 + 120) * (100 - 20) / (10 * 10)## [1] 3762.1.2 関数
通常のコマンドは、Rの関数を入力して実行します。
まずは、現在の時間を教えてくれるdate()という関数を試してみましょう。
# 現在の時刻を表示する関数
date()## [1] "Sat Jul 13 11:13:44 2019"関数には決まったパターンがあります。
date()を見て把握できる通り、関数は、必ず、関数名とそれに続く括弧から成り立っています。
上記の例であるdate()は、かっこの中に何も書いてありませんでしたが、
括弧の中には引数と呼ばれるものが入ることもあります。
引数は、「ひきすう」と読みます。
では、引数をとる関数を試してみましょう。sum()関数は、引数として渡された数字の合計を返してくれます。
# 引数として渡された数字を合計するsum()関数
sum(1, 2, 3, 4, 5)## [1] 15この様にカンマを使って区切ることで、関数には複数の引数を渡すことが出来ます。 関数の引数は、その各関数によって、どのような引数を取るのかが決まっています。 また、その引数の場所に意味があったり、 引数を省略すると自動的に既定値(デフォルト値)をとることもあります。 このような引数に関するルールについては、のちに学習することになりますが、 ここでは、まず、関数は引数を取ることがあるという基本的な事を把握できれば十分です。
2.2 履歴機能
先のsum()関数では、1から5までの数字を合計しました。 次は、1から6までの数字を合計したいとしましょう。 実際の計算作業においても、 一度行った計算の一部を調整して、再度、似たような計算を行うこともあると思います。 そんな、作業をサポートしてくれるのが履歴機能です。
コンソールにフォーカスがある状態で、カーソルキーの上矢印“↑”をーを押してください。 (図2.1) 前回実行したコマンドがプロンプト上に入力された状態になりましたか? 何度もこのカーソルの上矢印キーを押すと、 どんどん、前に入力して実行したコマンドに変わっていくはずです。 これを履歴機能と呼びます。 今度は、下矢印“↓”キーを押して下さい。 そうです、行き過ぎたら戻ればよいわけです。

Figure 2.1: キーボードのカーソルキー
このように、面倒で複雑なコマンドも1度入力してしまえば、 いつでも指一本で簡単に呼び出せるようになります。 ですから、似たようなコマンドは1から打ち込むことなく、 以前実行したコマンドを再度呼び出し、 必要な部分のみを修正するだけでよくなるので、入力が格段に簡単になります。
では、1から6までの合計値を計算してみてください。
# 履歴を活用して1から6の合計値を計算する
sum(1, 2, 3, 4, 5, 6)## [1] 212.3 補完機能
補完機能は、コマンドや変数を途中まで入力しさえすれば、 残りの部分を適切に補って入力してくれる機能です。
システムの保持している日時を出力してくれるSys.Date()関数で実践してみましょう。
プロンプトにSys.と入力してください。
入力している傍にメニューが現れ、その中にSys.Dateを見つけることができるはずです。(図2.2)
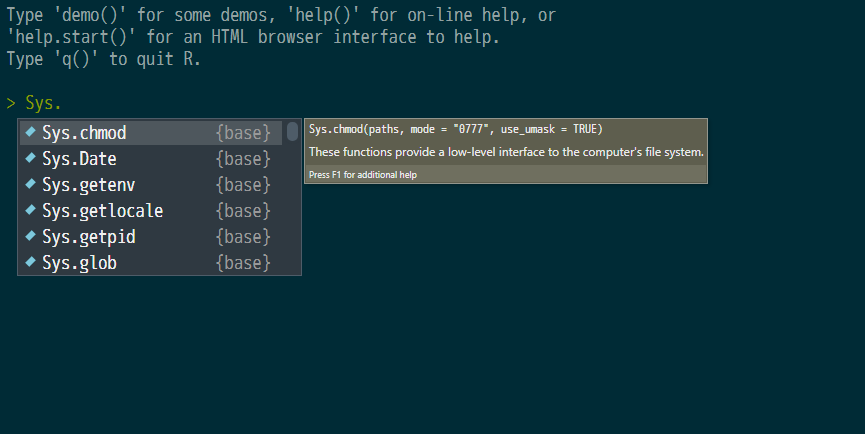
Figure 2.2: 補完メニュー
カーソルキーを使って、Sys.Dateを選択してから、
EnterキーかTabキーを押すと、プロンプトにSys.Date()が入力されます。
プロンプトへの入力中、補完メニューが出ていない状態で、Tabキーを押すと、
補完メニューを呼び出すことが出来ます。
補完メニューを呼び出したまま、入力を続けると、補完候補がリアルタイムで絞り込まれていきます。
補完候補は、コマンド等の綴りを正確に覚えていない時でも、
適当に試しながら探すことが出来ます。
例えば、よく使うlibrary()関数の正確なつづりに自信がなくても、
libさえわかれば、補完で何とかなります。
また、一旦、補完メニューを呼び出すと、連続した文字列でなくても絞り込みが効くようになります。
例えば、read.csv()関数という、csvファイルを読み込む関数があります。この関数を補完する際、
まず、rと一文字書いた時点で、tabキーで補完メニューを呼び出します。
この状態では当然、沢山の補完候補が表示されます。
しかし、この状態で、続けてcsv、
すなわち、rcsvとなるように入力を行って絞り込んでみてください。
このような補完検索のコツは、一旦、メニューを開くところにあります。
プロンプトに対して、メニューを開かず、いきなり、rcsvと入力してもうまくいきません。
さて、補完対象となるのは、関数名をはじめ、変数名、このあと紹介するファイルパス、ライブラリなどがあります。
また、RStudioでは、プロンプト上に限らず、ダイアログ内での入力でも補完が効くこともあります。
とりあえず、よくわからないときはTabキーで補完の問い合わせをしてみましょう。
プログラムでは、コードが一文字間違っても動きません。
コードの正確性をあげてケアレスミスを防止するため、そして、精神的ストレスを軽減するため
補完機能や、履歴機能を活用していきましょう。
2.4 複数行入力
ここまでに、コンソール上では、コマンド履歴の呼び出しや補完機能が働く事を紹介しました。 更に、コンソール上でのコマンド入力は複数行に分けて行うことが出来ます。
2.4.1 複数行入力と第2プロンプト “+”
例えば、試しに、date(とプロンプトに入力してください。
この時、通常、補完機能が働いて自動的にdate()と括弧を閉じて、
自動的にその括弧の間に、カーソルが来ますが、
その状態からカーソルを動かして右側の括弧を削除してdate(という状態にします。
それから、Enterキーを押します。
プロンプトがあった次の行の左端に + 文字が表示されるはずです。これは、第2プロンプトと呼ばれるもので、
「まだ続きのコマンド入力を受け付けていますよ」という事を示すプロンプト記号です。
これは加算演算子では無いことに注意しなければなりません。
では、ここで閉じ括弧 ) を入力してEnterキーを押してください。
date()コマンドが実行されます。(図2.3)
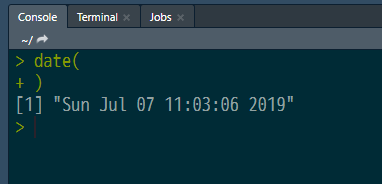
Figure 2.3: 複数行入力
コンソール上では、Enterキーが押された時に、現在の行内で括弧が閉じられていない時、または、 行末に演算子があり、右辺の入力がなされていない時には、コマンド入力が完成していないものと判断し、 エラーではなく、次の行に第2プロンプトを出して、さらなる入力を促してくれます。 例えば、関数の引数が沢山あったり、演算子を何個もつないだ長い計算式の場合、 1行がとても長くなって意味がわかりにくくなりますし、編集作業も大変になります。 このような場合に、コンソールの複数行入力機能は、便利に使えそうに思えます。
しかし、残念ながら実際に使ってみると、コマンド履歴が1行毎であったり、 前の行にもどって編集作業が出来ない等、 それほど便利ではありません。 ですから、実際にはこの機能を積極的に使う場面はないとおもいますが、 次の項で述べる、複数行入力のキャンセルの仕方は必ず覚えておきましょう。
2.4.2 複数行入力のキャンセル
複数行入力のキャンセルはEscキーで出来ます。
途中まで入力したコマンドをすべて放棄して、
元のプロンプトに戻ることが出来ます。
自分で、意図的に複数行入力を行った場合は、問題ないのですが、
初心者のうちは、複雑な式を入力している際に
誤って括弧の対が不ぞろいになっていている状態で
Enterキーを押してもコマンドが実行されず、
意図していない複数行入力の状態になってしまい、
パニックになることがあります。
そして、このように複数行入力になってしまったら、
コマンド入力が不完全であるうちは、
いくらEnterキーを押してもコマンドが実行されず、
次の行に + が表示されるだけでその状態から抜け出せなくなることがあります。
ですから、皆さんはまず、複数行入力というものが存在することを認識し、 間違ってその状態になってしまったら、 Escキーで抜け出すことが出来るということを必ず覚えておきましょう。
2.5 変数と代入
プログラミングをしたことが無い人ならば、 まずは単純に、変数とは名前の付いたデータの入れ物だと考えればOKです。
a という変数に、10という数を入れるならば、次のように書きます。
# 変数に値を代入する
a <- 10<-の部分は、変数にデータを代入する代入記号です。
<(小なり記号)と、-(ハイフン)の2文字を使って矢印のような形を書き込むことになりますが、
RStudio上では、Altキーと-ハイフンキーを同時押しすれば、一発で書き込むことが出来ます。
変数への代入を行うと、その代入された値はコンピューターの中に保持されます。
そして、RStudioは変数とその値についての情報を
右上ペインのEnvironmentタブにまとめて表示してくれます。(図2.4)
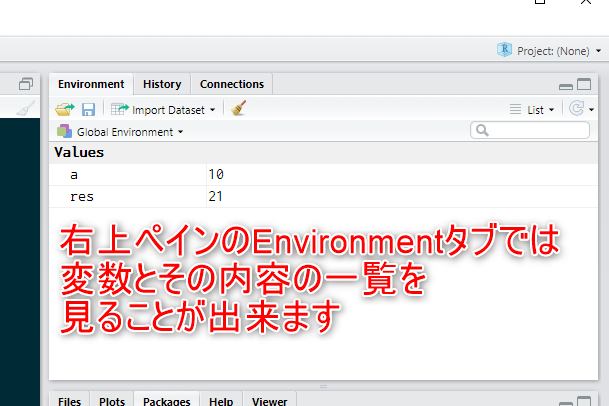
Figure 2.4: Environmentタブ
変数は、この保持する機能をもっているということを意識しましょう。 先ほど、1から6までの数字の合計値を計算しました。 しかし、実は、計算をして結果を表示させただけであり、 その結果を改めて他の計算に使おうと思っても既にそのデータはパソコン上にありません。 そこで、何らかの計算を行い、その計算結果を後から別の場所で使いたい場合には、 変数を使ってデータを保持しておく必要があるのです。
# 計算結果を代入する
res <- sum(1, 2, 3, 4, 5, 6)この変数resの内容は、右上ペインのEnvironmentタブに表示されている変数一覧で確認できるはずです。
では、1から6までの数字が合計されているので、それを使って、1から6までの数字の平均を求めてみましょう。 合計された数字をその個数6で割ればよいので、次のようになります。
# 計算結果を使って更に計算する
res / 6## [1] 3.5変数の性質については、これからたくさん学ぶべきものが出てきます。 しかし、まずは、代入記号を使って値を代入して、 その値を保持させ、これを後から使うことが出来るという点を把握しましょう。
2.6 ベクトル
ベクトルという単語を聞くと、高校数学で習った「方向と大きさを持った量」を思い浮かべるかもしれませんが、 Rでいうベクトルは、単なるデータの集合であり、高校数学のベクトルとは異なります。 もう一つ、ベクトルの発音で悩む必要はありません。日本語ではベクトルで大丈夫です。
プログラミングの世界では、ある一連のデータを扱うことが非常に多いです。 このため、Rだけでなくどんなプログラミング言語でも、データの集まりを扱うための仕組みがあります。 多くは、配列やリストという名前で、それらの仕組みは呼ばれています。
まずは、プログラミングの世界で扱う一連のデータとは、どんなものなのかを考えてみましょう。 例えば、ここで、ある人達にテストを受けてもらい、その結果が次のようになっているとします。
| 名前 | 点数 |
|---|---|
| レナード | 99 |
| シェルドン | 100 |
| ハワード | 65 |
| ラジェッシュ | 60 |
| ペニー | 3 |
このテストについての、最高点、最低点、平均点、中央値、標準偏差等を知るためには、 テスト結果の一つ一つの点数が個別を入手できても計算はできません。 一連の点数が全てそろった、まとまりとしてのデータが必要です。 このひとまとまりのデータを扱うために、Rではベクトルを使います。
2.6.1 ベクトルの作成
では、実際にベクトルを作りましょう。
ベクトルの作成には、c()関数を使います。c()関数の c はCombine(結合)の c です。
c()関数は、,カンマを使って複数の引数を渡し、ベクトルを作成します。
ここでは、上述のテストの一連の点数結果を複数の引数としてc()に渡して下さい。
# c()関数を使って一連のデータからベクトルを作成する
c(99, 100, 65, 60, 3)## [1] 99 100 65 60 3実行すると、すぐに結果としてベクトルが表示されます。 その単純な数字の並び、それがベクトルです。
ここで、先に説明を行った変数の事を思い出してください。 今、作成したベクトルは、変数に代入していないので、 コンピューター上に保持されていません。
ここで、練習問題です。
このテスト結果のベクトルをresultsという変数に代入し、このデータを保持して下さい。
# ベクトルを変数に代入してデータを保持する
results <- c(99, 100, 65, 60, 3)チェックしてみましょう。
- 履歴機能は使えましたか?
<-を上手に入力できましたか?
2.6.2 データの型とベクトルの性質
右上ペインのEnvironmentタブを見てみましょう。
そこに、results変数が加わっているはずでが、
変数の内容は、先ほどの単純な数字の10や21と異なり、次の様になっているはずです。
num [1:5] 99 100 65 60 3データの型
この情報は、3つの部分から構成されています。
はじめのnumは、データの型を表している部分です。
numは、は number すなわち、数値の略であり、
このベクトルのデータの型が数値型であることを表しています。
プログラミングを行う場合、その扱うデータには型というものが必ずあります。 数値型以外の典型的な型として、文字列型があります。
データ型の違いは、データの性質の違いを表しています。 ですから、データの型によって、出来る処理も異なります。 例えば、数値型のデータを使って、平均値等の計算ができますが、 文字列型のデータの平均値の計算は出来ません(意味論的にナンセンスという意味)。
ここで、この型を意識して、データを作成してみます。
まずは、数値型のデータを作製して、変数に代入してみます。
また、同時にstr()関数を使って、作成したデータの型を確認します。
strはstructure(構造)の略で、引数に与えたデータの構造を表示してくれる関数です。
# 数値型データの作成
n <- 123
str(n)## num 123何かのコマンドを使用するわけでは無く、 式の中で単純に数字を書けば、それが数値型のデータとして作成されます。
次は、文字列型のデータを作製して、変数に代入してみます。
# 文字列型データの作成
s <- "Hello World!"
str(s)## chr "Hello World!"文字列を二重引用符で囲むことで、文字列型のデータを作成できます。
str()関数の出力には、このデータの型がchrである書かれていますが、これはcharacteor(文字)の略です。
ベクトルの型
データに型があることがわかりました。 そして、実は複数データをとるベクトルにはこのデータの型について大きな約束事があります。 その約束事は、ベクトルを構成するデータの型は全て同じでなければならないということです。 ですから、データの型といってもいいですし、ベクトルの型といっても意味が通じます。 また、右上ペインのベクトルの内容表示に型は、データの型でありベクトルの型なのです。
2.6.3 ベクトルと要素
Environmentタブの表示には、型の次に[1:5]という表示があります。
この表示は、このベクトルには、1番から5番までのデータがありますということを示しています。つまり、この表示により、ベクトルに入っているデータの数を把握することが出来ます。
ベクトルは、ベクトルを構成する個別のデータは順序をもつという性質があります。 ですから、ベクトルの何番目のデータという表現を使うことで、 ベクトルを構成する個別のデータを一意に取り出すことが可能になっています。
このベクトルの要素を取り出すためには[]角括弧演算子を使います。
例えば、変数resultsに入っているベクトルの1番目の要素を取り出すには次のように書きます。
# ベクトルにアクセスする[]演算子
results[1]## [1] 99変数名の後ろに[]角括弧のペアを書き、
その中に何番目のデータにアクセスしたいのか、その数値を書き込みます。
2.6.4 ベクトルを使って計算
では、テストの点数がベクトルにまとまったので、
テストに関する平均を計算しましょう。
平均の計算にはmean()関数を使います。
このmean()関数の引数として、点数の入ったベクトルを渡す事で、平均の計算が出来ます。
# 平均を計算する
mean(results)## [1] 65.42.7 データフレーム
ベクトルは、順序のある一連のデータの集まりで1次元的データ構造でした。 これに対して、データフレームとは、2次元的なデータ構造をした、 表形式のデータの集まりです。 これは、エクセルの表のようなものだと認識してもらえれば結構です。
Rの大きな特徴の一つが、このデータフレームを簡単に処理できるところにあります。
Rには、沢山のサンプルデータがデータフレームの形で付随しています。
このサンプルの一つであるcarsデータを見てみましょう。
carsデータは、1920年代の自動車のスピードと停車できるまでの距離の関係の実験結果です。
コンソール上でプロンプトからcarsと呼び出せば、データが表示されます。
しかし、ここでは、cars_dataという変数を作ってそこに代入し、このデータを保持しましょう。
# データフレームのサンプルデータcars
cars_data <- cars2.7.1 データをView()でみる
右上ペインのEnvironmentタブにcars_dataが表示されます。
ここで、そのEnvironmentタブでcars_dataと書かれている部分をクリックして下さい。
そうすると、左上ペインに表形式のデータフレームが表示されます。(図2.5)
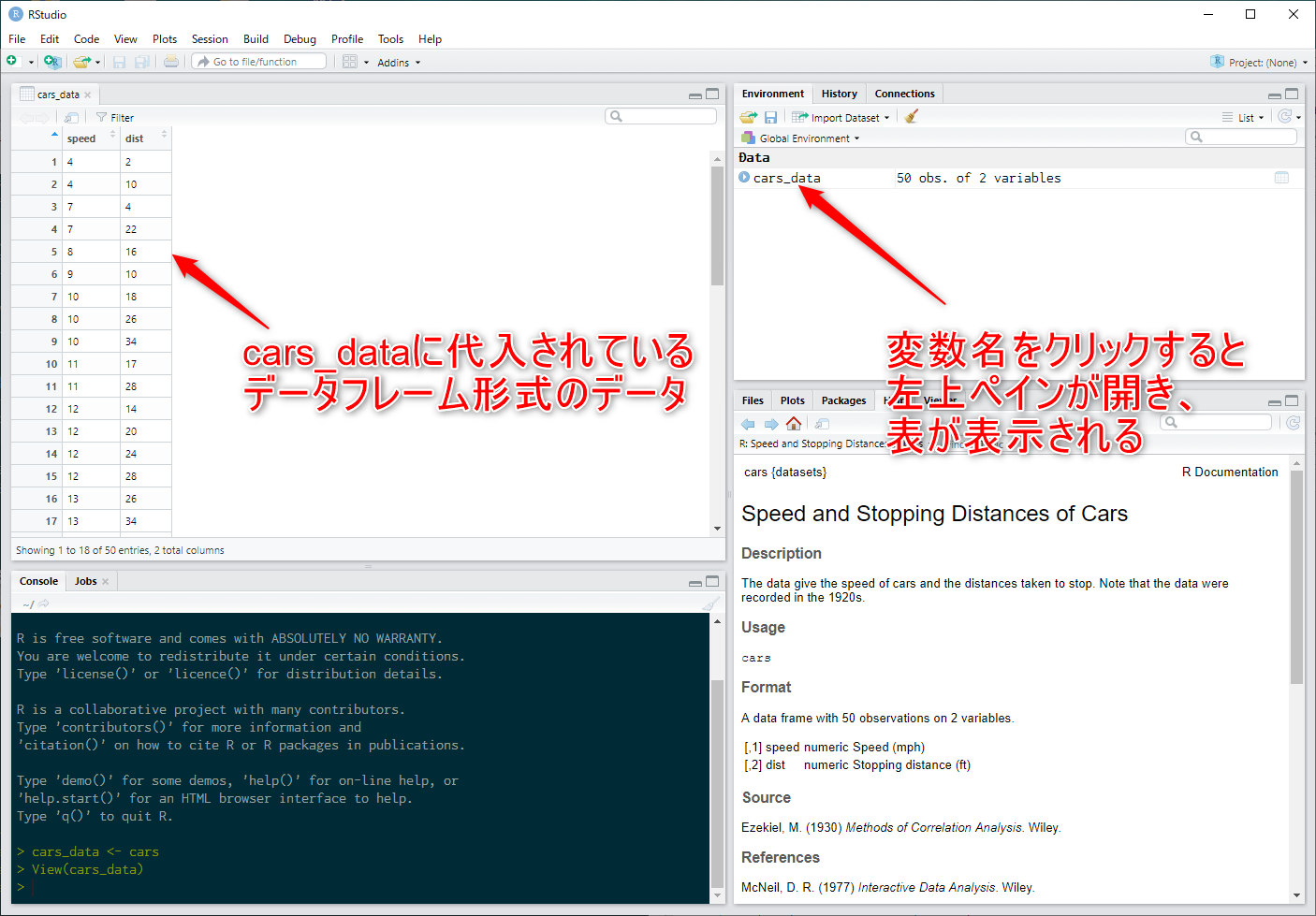
Figure 2.5: dataframeの表示
コンソールを見てみるとView(cars_data)というコマンドが書かれているのを見つけることが出来ます。
実は、変数名をクリックすることで、RStudioが自動的にフレームデータを見るためのコマンドを実行してくれているのです。
View()関数は、RStudioでデータを見るための関数です。
また、この関数は、Environmentタブの右端にある表を表すアイコンをクリックして呼び出すことも出来ます。
2.7.2 行と列
表形式のデータを扱うには、まず、行と列、その英語の省略形であるrowとcolを正確に暗記しましょう。覚え方は図2.6
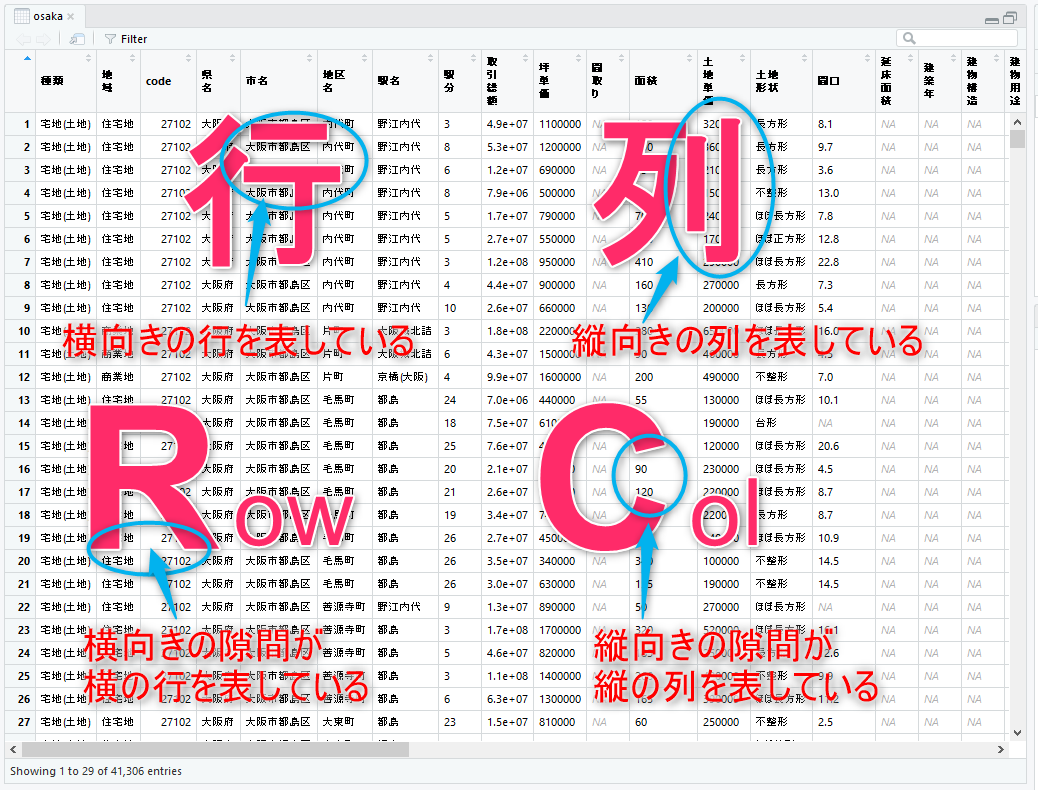
Figure 2.6: 行と列の覚え方
Rのデータ分析で扱う表形式のデータは整然データと呼ばれるルールに従ったデータになっています。 整然データでは、行と列はその役割が決まっており見やすさのために行と列を入れ替えたりすることは在りません。
carsデータを例に見ると、行はそれぞれの観測した車を表しており、 列は個々の観測で得られたスピードと距離という個々のデータの内容を表しています。 ですから、データフレームでは、行数がデータの件数、列数が各観測で観測したデータの種類の数を表します。
右上ペインのEnvironmentタブに表示されている情報は次のようなものでした。
cars_data 50 obs. of 2 variables50 obs. は、50件のデータであり、50行あること。 2 variablesは、2列のデータの種類があり、すなわち、2列であることを示しています。 つまり、この表示を確認することでデータフレームの大きさを把握することが出来ます。
2.7.3 整然データとキーワード
variablesは、変数という意味の英語です。obs.は、observationの略で、観測という意味の英語です。 これらは、整然データについて勉強をするとよく出てくるキーワードです。
| 行列 | 対応するキーワード |
|---|---|
| 行 | observation 観測 |
| 列 | variable 変数 |
データ分析を始める段階においては、 整然データの定義を精密に理解までしなくても、キーワードとして耳慣れておけば十分です。
2.7.4 列の名前と列へのアクセス
データフレームの列については、通常、その列データがなんであるかを示す列名が付けられています。
左上ペインに表示されているView(cars_data)の結果を見てください。列の一番上に、speedとdistと書かれているのを見つける事が出来るはずです。
(図2.5) これが、それぞれの列の列名です。
今度は、str()関数を使って、cars_dataの構造を確認してみましょう。
# データフレームcars_dataの構造を確認する
str(cars_data)## 'data.frame': 50 obs. of 2 variables:
## $ speed: num 4 4 7 7 8 9 10 10 10 11 ...
## $ dist : num 2 10 4 22 16 10 18 26 34 17 ...1行目で、このデータがdata.frameであることとその行と列の大きさの情報が示されます。
2行目以降は、各列についての情報が順に表示されています。
各列の情報は、$記号の後ろに、列名が表示され、その後ろにデータの型と具体的な内容の一部が表示されます。
すなわち、この方法でも、データフレームの列名を確認することが出来ます。
このcars_dataは、先に述べた通り、自動車のスピードと停車距離についての実験結果を表しています。
そして、今、確認した通り、スピードはspeed列に、停車距離はdist列にそれぞれ数値として入っています。
ここで、この実験が行われた際の平均スピードを求めたい場合、データフレームcars_dataから、speedの列データだけを取り出す必要が生じます。
これを行う一つの方法が$演算子です。
# cars_dataからspeed列を取り出す
cars_data$speed## [1] 4 4 7 7 8 9 10 10 10 11 11 12 12 12 12 13 13 13 13 14 14 14 14
## [24] 15 15 15 16 16 17 17 17 18 18 18 18 19 19 19 20 20 20 20 20 22 23 24
## [47] 24 24 24 25データフレームの後ろに$記号を書き、その後ろに列名を書きます。
50個の数値が表示されていますが、取り出された結果が何かを改めてstr()関数で確認していましょう。
# 取り出されたデータの構造を確認する
str(cars_data$speed)## num [1:50] 4 4 7 7 8 9 10 10 10 11 ...型名と要素の大きさが表示されました。これは、先に勉強したベクトルです。 これで、データフレームの列をベクトルとして取り出すことが出来るようになりました。
練習問題として、cars_dataで示される実験での、平均スピードを求めてみましょう。
# cars_dataで示される実験での平均スピード
mean(cars_data$speed)## [1] 15.4では、平均停車距離はどうでしょうか? 停車距離データが入っている列の列名が何かということを把握しましょう。
# cars_dataで示される実験での平均停車距離
mean(cars_data$dist)## [1] 42.98